
nVōq Hypothesis and Stable Text
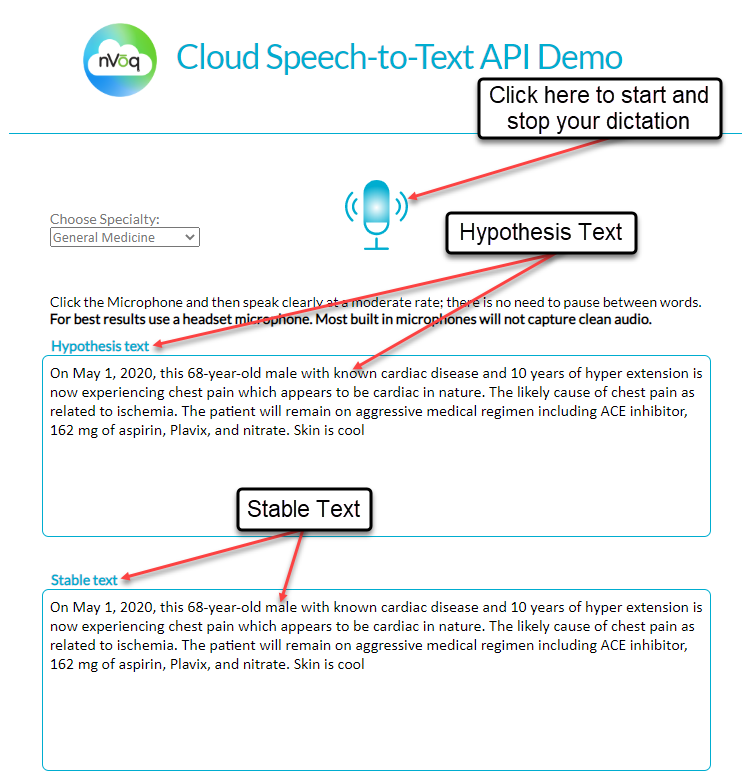
What is Hypothesis & Stable Text?Hypothesis Text is a first pass at transcribing the user’s spoken words and appears almost immediately after speaking. The main benefit for hypothesis text is the immediate feedback that the dictation process is working and allows the speaker to focus on the content of the dictation. Hypothesis text does not work with word markers.
Stable Text (aka Final Text) is the final form of the transcription that includes nVōq’s language processing plus all post processing updates, such as ITNs and substitutions. Stable text replaces the hypothesis text after 1 or 2 seconds. Stable text does work with word markers. Here is more information about stable text:
- Stable Text may also incorporate small context specific changes, as the dictation audio continues to be processed
- Stable Text returns occur in small chunks (incremental text return), reflecting just the new/additional text returned, since the prior audio chunk was processed
To see a demo of how hypothesis and stable text works, play the demo video below and expand window. The hypothesis text in the top box and the stable text is on the bottom box. You will notice that hypothesis text is immediately available while the stable text is about 1 to 2 seconds behind which is the final text. If you prefer, you can run the sample web dictation tool yourself and see how it works.
Facts about Hypothesis & Stable Text
- Hypothesis text and Stable text transcriptions can be returned by either WebSockets or HTTP
- Hypothesis text always includes the entirety of the dictation (cumulative text return), up to that point in time – this facilitates full replacement of ALL the hypothesis text, with each returning chunk